Learning Analytics and Educational Data Mining are neighboring fields, not synonyms.학습분석(Learning Analytics)과 교육 데이터 마이닝(Educational Data Mining)은 인접 분야이지, 동의어가 아니다.
This guide explains the difference for new researchers using a 2016-2025 proceedings corpus from LAK and EDM. The practical distinction is not only technical. LA asks how learning evidence becomes interpretation, design, and action. EDM asks how educational data can be modeled, inferred, predicted, and validated.이 가이드는 신규 연구자에게 그 차이를 LAK·EDM의 2016–2025년 프로시딩(proceedings) 코퍼스(corpus)로 설명한다. 실질적 구분은 기술적인 데에만 있지 않다. LA는 학습 증거가 어떻게 해석·설계·행동으로 이어지는지를 묻는다. EDM은 교육 데이터를 어떻게 모델링·추론·예측·검증할 수 있는지를 묻는다.
The fastest usable distinction가장 빠르게 쓸 수 있는 구분
For onboarding, treat LA and EDM as two lenses on the same evidence ecosystem. They overlap in data sources, modeling methods, and educational problems, but they foreground different questions.입문자에게는 LA와 EDM을 같은 증거 생태계를 보는 두 렌즈로 다루는 편이 좋다. 데이터 출처, 모델링 방법, 교육적 문제는 겹치지만, 각자 전면에 내세우는 질문이 다르다.
From data to pedagogical action데이터에서 교육 실천(pedagogical action)으로
Learning Analytics is strongest when the contribution explains how data traces support interpretation, feedback, reflection, advising, dashboards, self-regulated learning, institutional decision-making, or learning design.학습분석은 데이터 흔적(trace)이 어떻게 해석, 피드백, 성찰, 어드바이징(advising), 대시보드(dashboard), 자기조절 학습(self-regulated learning, SRL), 기관 의사결정, 학습 설계(learning design)로 이어지는지를 설명하는 연구에서 가장 큰 강점을 보인다.
From data to validated models데이터에서 검증된 모델로
Educational Data Mining is strongest when the contribution develops or evaluates models for prediction, knowledge tracing, assessment, recommendation, item response, tutoring systems, or algorithmic inference.교육 데이터 마이닝은 예측(prediction), 지식 추적(knowledge tracing), 평가, 추천(recommendation), 문항 반응(item response), 튜터링 시스템(tutoring system), 알고리즘적 추론을 위한 모델을 개발하거나 평가하는 연구에서 가장 큰 강점을 보인다.
Evidence pipeline. Both fields begin with educational traces. LA turns traces toward interpretation, feedback, and design action; EDM turns traces toward features, models, validation, and inference.증거 파이프라인. 두 분야 모두 교육적 흔적에서 출발한다. LA는 그 흔적을 해석·피드백·설계 행동 쪽으로 돌리고, EDM은 흔적을 피처·모델·검증·추론 쪽으로 돌린다.
Where Learning Analytics comes from학습분석의 기원
Learning Analytics grew around the problem of making digital traces useful for learning and teaching. SoLAR describes LA as collecting, analyzing, interpreting, and communicating learner data to provide theoretically relevant and actionable insights. That wording matters: LA is not just analysis. It includes interpretation, communication, theory, human-centered design, and the practical question of who can act on the evidence.학습분석은 디지털 흔적(digital trace)을 학습과 교수에 유용하게 만드는 문제 주변에서 자라났다. SoLAR는 LA를 이론적으로 적합하고 실행 가능한(actionable) 통찰을 제공하기 위해 학습자 데이터를 수집·분석·해석·소통하는 활동으로 정의한다. 이 표현이 중요하다: LA는 단순한 분석이 아니다. 해석, 소통, 이론, 인간 중심 설계(human-centered design), 그리고 누가 그 증거에 따라 행동할 수 있는가라는 실질적 질문을 포함한다.
As a community, LA took shape through SoLAR and the International Conference on Learning Analytics and Knowledge, whose first conference was in 2011. Historically, LAK positioned the field at the intersection of learning sciences, educational technology, analytics, visualization, institutional research, and design. That is why LA papers often ask whether a dashboard, feedback loop, advising signal, or analytics intervention changes what learners, teachers, or institutions can see and do.공동체로서 LA는 SoLAR와 2011년 첫 번째 LAK(Learning Analytics and Knowledge) 학회를 통해 형태를 갖췄다. 역사적으로 LAK는 학습과학(learning sciences), 교육공학(educational technology), 분석학(analytics), 시각화(visualization), 기관 연구(institutional research), 설계의 교차점에 분야를 위치시켜 왔다. 그래서 LA 논문은 대시보드, 피드백 루프(feedback loop), 어드바이징 신호, 분석 개입(analytics intervention)이 학습자·교수자·기관이 보고 행할 수 있는 것을 바꾸는지를 자주 묻는다.
Where Educational Data Mining comes from교육 데이터 마이닝의 기원
Educational Data Mining grew from data mining, machine learning, psychometrics, intelligent tutoring systems, student modeling, and large-scale educational log analysis. The International Educational Data Mining Society was founded in 2011, formalizing a community that had already been building methods for educational data, tutoring systems, and student modeling.교육 데이터 마이닝은 데이터 마이닝(data mining), 머신러닝(machine learning), 심리측정학(psychometrics), 지능형 튜터링 시스템(intelligent tutoring system, ITS), 학생 모델링(student modeling), 대규모 교육 로그 분석에서 자라났다. 국제 교육 데이터 마이닝 학회(IEDMS)는 2011년에 공식화되었으며, 이미 수년간 교육 데이터·튜터링 시스템·학생 모델링 기법을 만들어 온 공동체를 제도화했다.
CMU DataLab's overview frames EDM around mining and analyzing data collected during teaching, validating findings at scale, predicting knowledge and dropout risk, and supporting adaptivity and personalization. That methodological origin explains why EDM papers often foreground model validity, prediction, knowledge tracing, item response, recommendation, algorithmic comparison, feature engineering, and benchmark-style evaluation. The educational goal remains important, but the center of gravity is usually the computational model and the evidence that it works.CMU DataLab의 개관은 EDM을 교수 과정에서 수집된 데이터를 마이닝·분석하고, 발견을 대규모로 검증하며, 지식과 중도 탈락(dropout) 위험을 예측하고, 적응성(adaptivity)과 개인화(personalization)를 지원하는 활동으로 틀짓는다. 이런 방법론적 기원 덕분에 EDM 논문은 모델 타당도(model validity), 예측, 지식 추적, 문항 반응, 추천, 알고리즘 비교, 피처 엔지니어링(feature engineering), 벤치마크 평가(benchmark evaluation)를 전면에 내세우는 경향이 있다. 교육적 목표는 여전히 중요하지만, 무게중심은 보통 계산 모델(computational model)과 그것이 작동한다는 증거에 있다.
Working thesis for a column한 줄 작업 가설
LA asks whether educational data becomes meaningful and actionable for learners, teachers, designers, or institutions. EDM asks whether educational data can be transformed into robust computational evidence. A strong hybrid paper makes both chains visible: model validity and educational actionability.LA는 교육 데이터가 학습자·교수자·설계자·기관에 의미 있고 실행 가능해지는지를 묻는다. EDM은 교육 데이터가 견고한 계산적 증거로 변환될 수 있는지를 묻는다. 강한 하이브리드 논문은 두 가지 사슬—모델 타당성과 교육적 실행 가능성—을 모두 가시화한다.
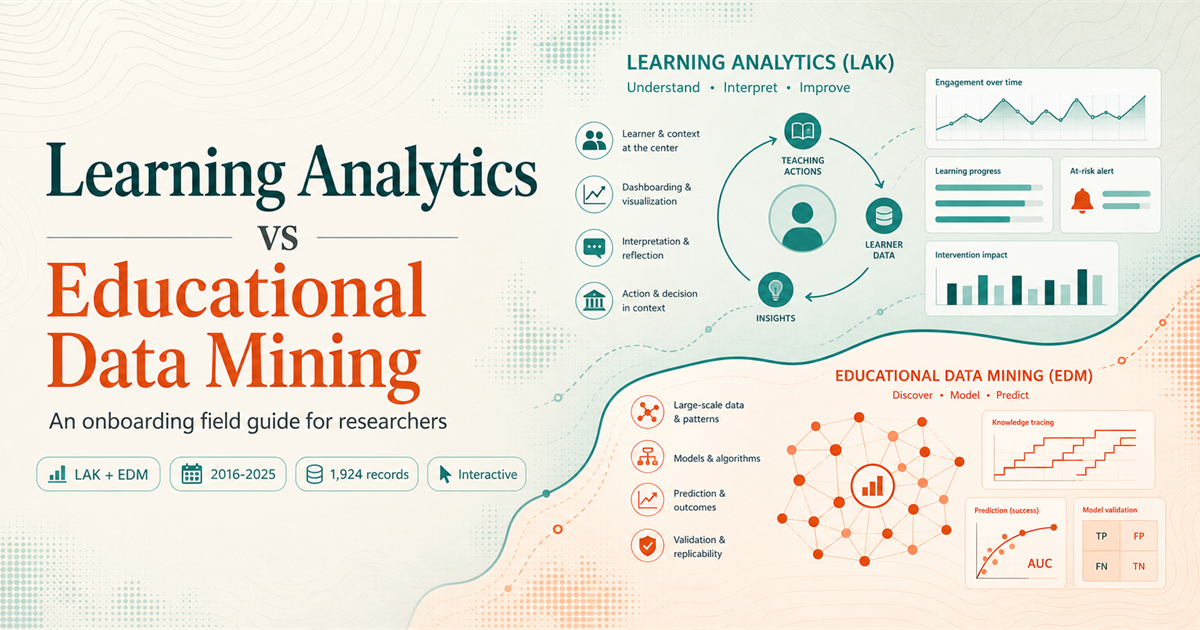
Field map. LA is framed as interpretation, communication, and action around learner data; EDM is framed as modeling, prediction, and validation over educational traces.분야 지도. LA는 학습자 데이터에 대한 해석·소통·행동의 틀로, EDM은 교육적 흔적에 대한 모델링·예측·검증의 틀로 그려진다.
Why these became two fields왜 두 분야로 나뉘게 되었나
The distinction is easier to understand historically than by definitions alone. Both communities responded to the same shift: learning activity was moving into digital environments, producing traces at a scale that traditional classroom observation, testing, and institutional reporting could not fully use.이 구분은 정의보다 역사적으로 이해하는 편이 쉽다. 두 공동체 모두 같은 변화에 반응했다. 학습 활동이 디지털 환경으로 이동하면서, 전통적인 수업 관찰·시험·기관 보고가 다 활용할 수 없을 정도의 규모로 흔적이 생산되기 시작한 것이다.
The shared trigger공통의 출발점
LMS platforms, MOOCs, intelligent tutors, assessment systems, discussion forums, and clickstream logs made learning visible as event data. Both LA and EDM ask what can be learned from those traces, but they developed different answers about what counts as the central contribution.LMS 플랫폼, MOOC, 지능형 튜터(intelligent tutor), 평가 시스템, 토론 포럼, 클릭스트림 로그(clickstream log)가 학습을 사건 데이터(event data)로 가시화했다. LA와 EDM 모두 그 흔적에서 무엇을 배울 수 있는지를 묻지만, 무엇을 핵심 기여로 칠 것인가에 대해 다른 답을 발전시켰다.
LA's institutional and design pullLA의 기관·설계 지향
Learning Analytics formed around dashboards, feedback, advising, institutional decision-making, learning design, ethics, and stakeholder action. Its recurring problem is not only whether a model works, but whether evidence becomes meaningful to learners, teachers, designers, and organizations.학습분석은 대시보드, 피드백, 어드바이징, 기관 의사결정, 학습 설계, 윤리, 이해관계자(stakeholder) 행동을 중심으로 형성되었다. 반복되는 문제는 모델이 작동하는가뿐 아니라, 증거가 학습자·교수자·설계자·조직에 의미 있게 다가가는가이다.
EDM's modeling and inference pullEDM의 모델링·추론 지향
Educational Data Mining formed around discovering patterns in educational data, building models of students and learning environments, and validating algorithms. Its recurring problem is not only whether data are actionable, but whether the computational evidence is robust, predictive, and reusable.교육 데이터 마이닝은 교육 데이터에서 패턴을 발견하고, 학생과 학습 환경의 모델을 만들며, 알고리즘을 검증하는 일을 중심으로 형성되었다. 반복되는 문제는 데이터가 실행 가능한가뿐 아니라, 계산적 증거가 견고하고 예측력 있고 재사용 가능한가이다.
Community infrastructure공동체 인프라
LAK's first conference was held in 2011, and SoLAR now frames Learning Analytics as an academic discipline and practice field concerned with collection, analysis, interpretation, and communication of learner data for theoretically relevant and actionable insight. The Journal of Learning Analytics extends that identity by emphasizing connections among researchers, developers, and practitioners.LAK의 첫 학회는 2011년에 열렸고, SoLAR는 학습분석을 이론적으로 적합하고 실행 가능한 통찰을 위해 학습자 데이터를 수집·분석·해석·소통하는 학문이자 실천 분야로 정의한다. Journal of Learning Analytics는 연구자·개발자·실무자 사이의 연결을 강조하면서 그 정체성을 확장한다.
EDM infrastructureEDM 인프라
The International Educational Data Mining Society was founded in July 2011, after several years of EDM conference activity. IEDMS defines EDM as developing methods for exploring unique, increasingly large-scale educational data and using those methods to better understand students and learning settings. JEDM and the EDM conference series make the methodological community explicit.국제 교육 데이터 마이닝 학회(IEDMS)는 EDM 학회 활동이 수년간 진행된 후 2011년 7월에 설립되었다. IEDMS는 EDM을 점점 커지는 고유한 교육 데이터를 탐구하기 위한 방법을 개발하고, 그 방법을 이용해 학생과 학습 환경을 더 잘 이해하는 활동으로 정의한다. JEDM과 EDM 학회 시리즈가 그 방법론 공동체를 명시화한다.
Start here: HLA 2017먼저 읽기: HLA 2017
The first Handbook of Learning Analytics is useful for origin stories: theory, measurement, ethics, dashboards, predictive modeling, multimodal analytics, feedback, institutional adoption, and a critical LA/EDM chapter. It is the best first pass for seeing LA as a broad socio-technical field.첫 Handbook of Learning Analytics는 기원 이야기를 보기에 좋다: 이론, 측정, 윤리, 대시보드, 예측 모델링, 멀티모달(multimodal) 분석학, 피드백, 기관 도입, 그리고 LA/EDM 비평 챕터까지. LA를 광범위한 사회기술적(socio-technical) 분야로 보기에 가장 좋은 첫 패스다.
Then read: HLA 2022다음 읽기: HLA 2022
The second edition updates the field after several years of growth. It is especially useful for newcomers who want modern coverage of predictive modeling, NLP, multimodal learning analytics, SRL, collaboration, teacher/student-facing analytics, fairness, policy, and human-centered feedback.2판은 수년간의 성장 이후 분야를 갱신한다. 예측 모델링, NLP, 멀티모달 학습분석, SRL, 협력, 교수자/학생 대면 분석학, 공정성, 정책, 인간 중심 피드백을 현대적으로 다룬 자료를 원하는 입문자에게 특히 유용하다.
EDM baseline: 2010 handbookEDM 기준선: 2010 핸드북
The Handbook of Educational Data Mining gives the EDM baseline: classifiers, clustering, association rules, sequence/process mining, PSLC DataShop, q-matrices, skill models, Bayesian networks, recommendation, affect, validation, and case studies from intelligent learning environments.Handbook of Educational Data Mining은 EDM의 기준선을 제공한다: 분류기(classifier), 군집화(clustering), 연관 규칙(association rules), 시퀀스/프로세스 마이닝(sequence/process mining), PSLC DataShop, q-매트릭스(q-matrix), 스킬 모델(skill model), 베이지안 네트워크(Bayesian network), 추천, 정서(affect), 검증(validation), 그리고 지능형 학습 환경의 사례 연구.

Reading roadmap. Use the LA handbooks to understand the socio-technical field, then use the EDM handbook to understand the modeling tradition, then read recent LAK/EDM proceedings as current evidence of field movement.독서 로드맵. LA 핸드북으로 사회기술적 분야를 파악하고, EDM 핸드북으로 모델링 전통을 파악한 다음, 최근 LAK/EDM 프로시딩을 분야 흐름의 최신 증거로 읽으세요.
Beginner reading rule초보자 독해 규칙
When reading a paper, ask what the paper wants credit for. If the paper wants credit for a better educational decision, feedback loop, stakeholder-facing representation, or learning-design implication, read it through an LA lens. If it wants credit for a better model, inference method, prediction, trace representation, or benchmark result, read it through an EDM lens. If it wants both, evaluate both chains separately.논문을 읽을 때, 그 논문이 무엇으로 인정받고 싶은지를 물어라. 더 나은 교육적 의사결정·피드백 루프·이해관계자 표상·학습 설계 함의로 인정받고 싶다면 LA 렌즈로 읽는다. 더 나은 모델·추론 방법·예측·흔적 표상·벤치마크 결과로 인정받고 싶다면 EDM 렌즈로 읽는다. 둘 다라면 두 사슬을 따로 평가한다.
How this dataset and analysis were built이 데이터셋과 분석은 어떻게 만들어졌는가
This page is based on a reproducible metadata and title-level NLP workflow. The goal is onboarding and field comparison, not a final systematic review.이 페이지는 재현 가능한 메타데이터(metadata)·제목 수준 NLP 워크플로(workflow)에 기반한다. 목표는 입문자 안내와 분야 비교이며, 최종적인 체계적 문헌 고찰(systematic review)은 아니다.
Define the corpus boundary코퍼스 경계 정의
The scope is LAK 2016-2025 and EDM 2016-2025. Each venue-year was treated as a proceedings table of contents, not as a broad web search. This keeps the comparison bounded to two field conferences over the same ten-year window.범위는 LAK 2016–2025와 EDM 2016–2025이다. 각 학회-연도를 광범위한 웹 검색이 아니라 프로시딩 목차로 다루었다. 두 학회의 같은 10년 창문 안에서 비교가 한정된다.
Extract DBLP metadata by table-of-contents facet목차 패싯으로 DBLP 메타데이터 추출
For each venue-year pair, the script queried the DBLP publication API with a TOC facet such as toc:db/conf/lak/lak2025.bht: or toc:db/conf/edm/edm2025.bht:. Stored fields include venue, year, title, authors, author count, pages, DBLP type, key, DOI when present, electronic edition URL, DBLP URL, access flag, and source query URL.각 학회-연도 쌍마다 스크립트가 DBLP 출판 API에 toc:db/conf/lak/lak2025.bht: 또는 toc:db/conf/edm/edm2025.bht: 같은 TOC(목차) 패싯(facet)으로 질의했다. 저장된 필드는 학회, 연도, 제목, 저자, 저자 수, 페이지, DBLP 유형, 키, DOI(있을 때), 전자판 URL, DBLP URL, 접근 플래그, 원본 질의 URL이다.
Remove obvious non-research records명백한 비연구 레코드 제거
The raw extraction contained 1,953 non-editorship records. A title-based analytic filter removed 29 obvious meta records containing terms such as workshop, tutorial, doctoral consortium, proceedings, front matter, preface, panel, keynote, and symposium. The final analytic corpus contains 1,924 records: 824 LAK and 1,100 EDM.원본 추출에는 비편집위원 레코드 1,953건이 포함되어 있었다. 제목 기반 분석 필터가 workshop, tutorial, doctoral consortium, proceedings, front matter, preface, panel, keynote, symposium 같은 용어를 포함한 메타 레코드 29건을 제거했다. 최종 분석 코퍼스는 1,924건이다: LAK 824건, EDM 1,100건.
Create first-pass method and data-context tags1차 방법·데이터 맥락 태그 생성
Title-keyword heuristics were used to mark broad method signals such as prediction/modeling, knowledge tracing, dashboard/visualization, NLP/discourse/text, multimodal/sensor, network/sequence/process, causal/experimental, LLM/GenAI, fairness/privacy/ethics, and learning design/SRL. Data-context tags include LMS/MOOC/logs, assessment/grades, collaboration/discourse, tutoring/intelligent systems, writing/text artifacts, multimodal/sensor, and dashboard/user study. These are directional screening tags, not final human-coded categories.제목 키워드 휴리스틱(heuristic)으로 예측/모델링, 지식 추적, 대시보드/시각화, NLP/담화(discourse)/텍스트, 멀티모달/센서(sensor), 네트워크/시퀀스/프로세스, 인과(causal)/실험, LLM/생성형 AI(GenAI), 공정성(fairness)/프라이버시/윤리, 학습 설계/SRL 같은 광범위한 방법 신호를 표시했다. 데이터 맥락 태그는 LMS/MOOC/로그, 평가/성적, 협력/담화, 튜터링/지능형 시스템, 쓰기/텍스트 산출물(artifact), 멀티모달/센서, 대시보드/사용자 연구(user study)를 포함한다. 이는 방향성 스크리닝(screening) 태그이며, 최종적인 인간 코딩(human coding) 범주가 아니다.
Run title-level semantic NLP제목 수준 의미 NLP 실행
Paper titles were embedded with sentence-transformers/all-mpnet-base-v2. BERTopic was run over the precomputed embeddings using UMAP for dimensionality reduction, HDBSCAN for clustering, and c-TF-IDF for topic representation. The run produced 22 clusters including the outlier/mixed topic. Topic labels are c-TF-IDF top words, not generated claims.논문 제목을 sentence-transformers/all-mpnet-base-v2로 임베딩(embedding)했다. BERTopic을 사전 계산 임베딩 위에서 실행했고, 차원 축소(dimensionality reduction)에는 UMAP, 군집화에는 HDBSCAN, 토픽 표상(topic representation)에는 c-TF-IDF를 사용했다. 실행 결과는 이상치(outlier)/혼합 토픽을 포함한 22개 군집(cluster)이다. 토픽 라벨은 c-TF-IDF 상위 단어이며, 생성된 주장이 아니다.
Build comparative tables and interactive visuals비교표와 인터랙티브 시각자료 구축
The page uses venue-year counts, method/data tag percentages, topic-by-venue counts, and selected topic-by-year counts. Counts are shown interactively so readers can inspect the difference between raw volume, within-venue signal, and topic distinctiveness.이 페이지는 학회-연도 카운트, 방법/데이터 태그 백분율, 학회별 토픽 카운트, 그리고 선택된 토픽-연도 카운트를 사용한다. 카운트는 인터랙티브하게 표시되어 독자가 전체 규모, 학회 내 신호, 토픽 변별력의 차이를 검토할 수 있다.
State the interpretation boundary해석의 경계 명시
The current evidence supports onboarding-level claims about field tendencies. It should not be cited as a publication-grade systematic review until abstracts or full texts are enriched through DOI/OpenAlex/Semantic Scholar/Crossref, and a stratified sample is human-coded for methods, data sources, educational setting, and contribution type.현재 증거는 분야 경향에 대한 입문자 수준의 주장을 지원한다. 초록이나 본문이 DOI/OpenAlex/Semantic Scholar/Crossref로 보강되고, 층화 표본(stratified sample)이 방법·데이터 출처·교육 환경·기여 유형에 대해 인간 코딩되기 전에는 출판 등급의 체계적 문헌 고찰로 인용되어서는 안 된다.
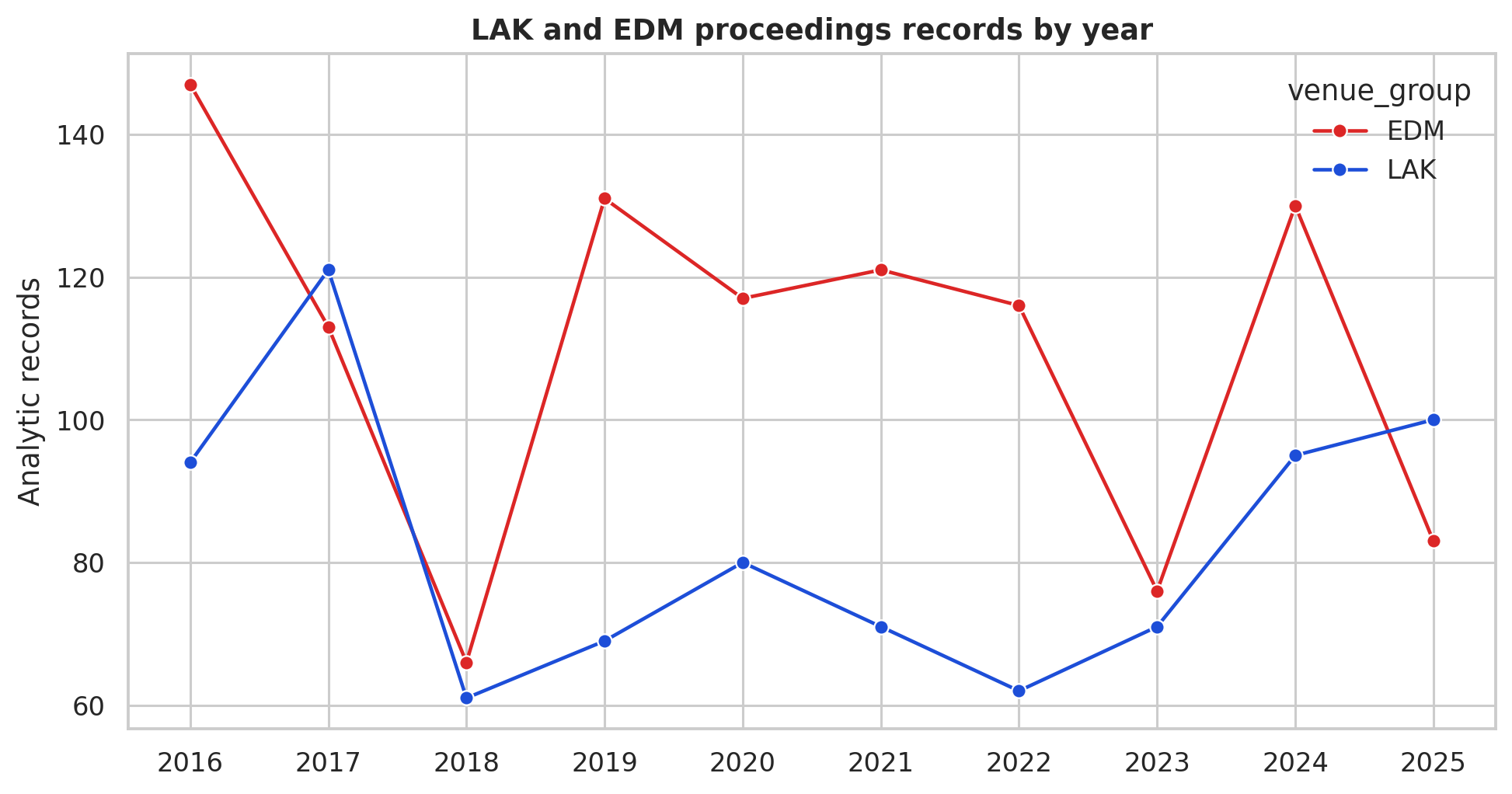
Proceedings volume is uneven, so normalize claims프로시딩 규모가 고르지 않으므로 주장을 정규화하라
EDM has more analytic records in this extraction, but the difference changes by year. Interpret method or topic prevalence as percentages or within-venue patterns when possible.이 추출에서는 EDM의 분석 레코드가 더 많지만, 그 차이는 연도에 따라 변한다. 가능하면 방법이나 토픽 빈도를 백분율 또는 학회 내 패턴으로 해석하라.
EDM contributes more records overall in this ten-year extraction, especially in 2016, 2019-2022, and 2024. LAK is smaller in several years but reaches comparable or higher volume in 2017 and 2025. This means raw topic counts can mislead: a topic can look larger in EDM partly because the EDM corpus is larger. For field comparison, use within-venue percentages, distinctiveness ratios, and topic trajectories.EDM은 이 10년 추출에서 전체적으로 더 많은 레코드를 기여하며, 특히 2016, 2019–2022, 2024년에 그렇다. LAK는 여러 해에 더 작지만 2017년과 2025년에는 비슷하거나 더 큰 규모에 이른다. 이는 원시 토픽 카운트가 오해를 줄 수 있음을 뜻한다: EDM 코퍼스가 더 크기 때문에 토픽이 EDM에서 더 커 보일 수 있다. 분야 비교에는 학회 내 백분율, 변별력(distinctiveness) 비율, 토픽 궤적(trajectory)을 사용하라.
Method and data-context signals show the field personalities방법·데이터 맥락 신호가 분야의 성격을 보여 준다
These are conservative title-keyword heuristics. They are useful for onboarding and direction-finding, but not a substitute for abstract/full-text coding.이는 보수적인 제목 키워드 휴리스틱이다. 입문자 안내와 방향 잡기에는 유용하지만, 초록/본문 코딩의 대체물은 아니다.
The method tags show the expected split without making it absolute. EDM has a larger prediction/modeling signal, while LAK has stronger learning design/SRL, dashboard/visualization, fairness/privacy/ethics, multimodal/sensor, and network/sequence/process signals. The data-context view adds nuance: EDM is more assessment/grades and tutoring/intelligent-systems heavy, while LAK is relatively stronger in LMS/MOOC/logs, dashboard/user-study, multimodal/sensor, and collaboration/discourse contexts.방법 태그는 절대화하지 않으면서 예상된 분리를 보여 준다. EDM은 더 큰 예측/모델링 신호를 가지며, LAK는 더 강한 학습 설계/SRL, 대시보드/시각화, 공정성/프라이버시/윤리, 멀티모달/센서, 네트워크/시퀀스/프로세스 신호를 가진다. 데이터 맥락 보기는 뉘앙스를 더한다: EDM은 평가/성적과 튜터링/지능형 시스템 비중이 더 높고, LAK는 LMS/MOOC/로그, 대시보드/사용자 연구, 멀티모달/센서, 협력/담화 맥락에서 상대적으로 더 강하다.
Because many titles are uncoded, these bars should be treated as directional signals. They are best used to teach newcomers what to look for in abstracts, not to make final prevalence claims.많은 제목이 미코딩이므로, 이 막대들은 방향성 신호로 다뤄야 한다. 입문자에게 초록에서 무엇을 찾아야 하는지 가르치는 데 가장 잘 쓰이고, 최종 빈도 주장에 쓰는 것이 아니다.
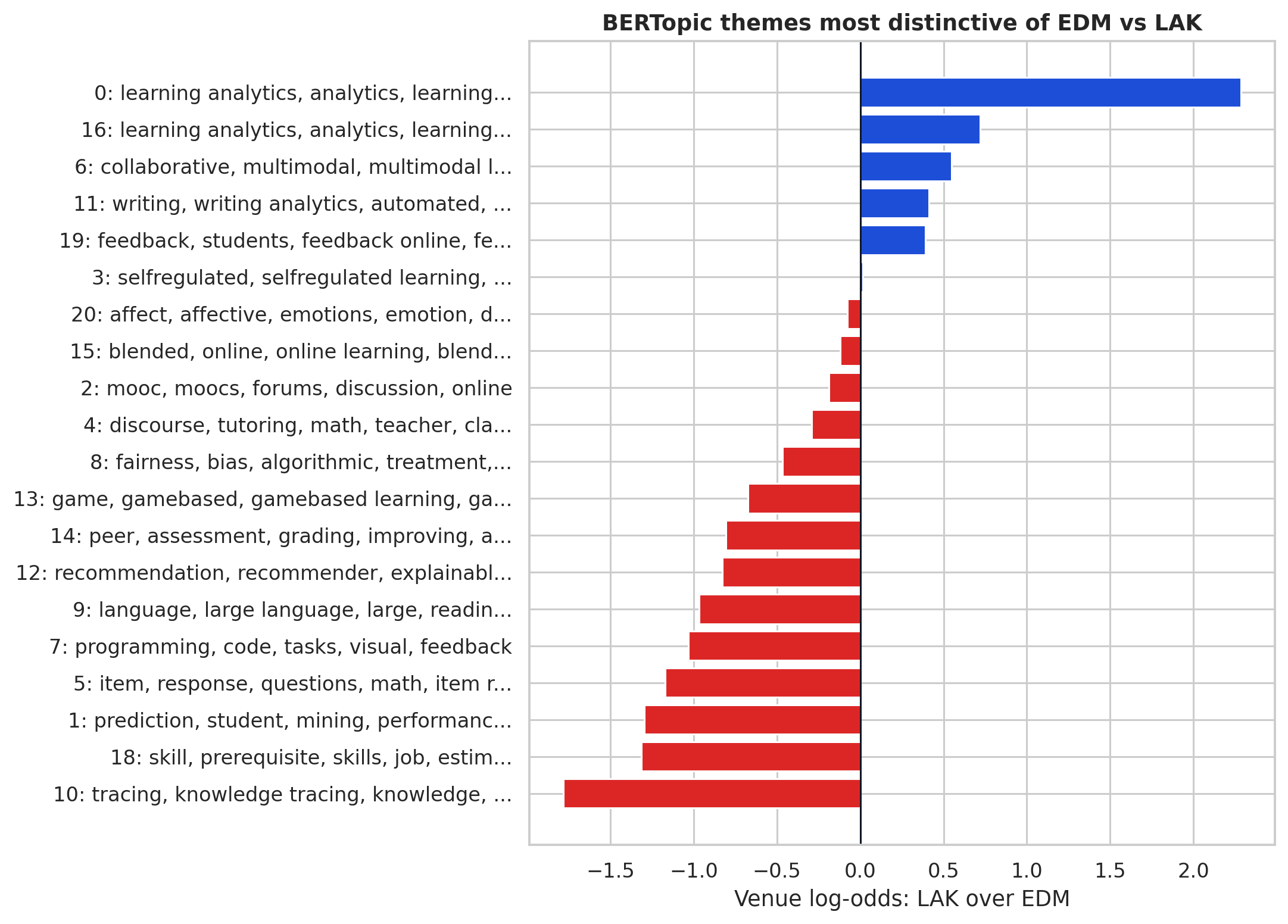
Semantic topics make the contrast sharper의미 토픽이 대비를 더 선명하게 만든다
MPNet + BERTopic over titles surfaces a recognizable split: LAK is more distinctive around learning analytics, dashboards, collaboration, multimodal learning, and writing analytics; EDM is more distinctive around prediction, knowledge tracing, item response, programming tasks, and recommendation systems.제목에 대한 MPNet + BERTopic은 인식 가능한 분리를 드러낸다: LAK는 학습분석, 대시보드, 협력, 멀티모달 학습, 쓰기 분석에서 더 변별력 있고, EDM은 예측, 지식 추적, 문항 반응, 프로그래밍 과제, 추천 시스템에서 더 변별력 있다.
The semantic topics show that the fields are organized around different prototypical contributions. LAK-distinctive topics are not merely "data analysis" topics; they are about analytics as a learning support infrastructure: dashboards, feedback, writing analytics, collaboration, multimodal learning, and learning analytics as a named field. EDM-distinctive topics are closer to educational machine learning and student modeling: prediction, knowledge tracing, item response, programming tasks, recommendation, and skill/prerequisite estimation.의미 토픽은 두 분야가 다른 원형적 기여를 중심으로 조직되어 있음을 보여 준다. LAK 변별 토픽은 단순한 "데이터 분석" 토픽이 아니다. 학습 지원 인프라로서의 분석에 관한 것이다: 대시보드, 피드백, 쓰기 분석, 협력, 멀티모달 학습, 명명된 분야로서의 학습분석. EDM 변별 토픽은 교육 머신러닝과 학생 모델링에 더 가깝다: 예측, 지식 추적, 문항 반응, 프로그래밍 과제, 추천, 스킬/선수학습 추정.
The overlap is important. MOOCs, discourse, self-regulated learning, affect, and multimodal data appear in both fields. The difference is usually how the paper frames the contribution: actionability and sensemaking versus model development and validation.중첩(overlap)이 중요하다. MOOC, 담화, 자기조절 학습, 정서, 멀티모달 데이터는 두 분야 모두에 등장한다. 차이는 보통 논문이 기여를 어떻게 프레이밍하는가에 있다: 실행 가능성과 의미 형성(sensemaking) 대 모델 개발과 검증.
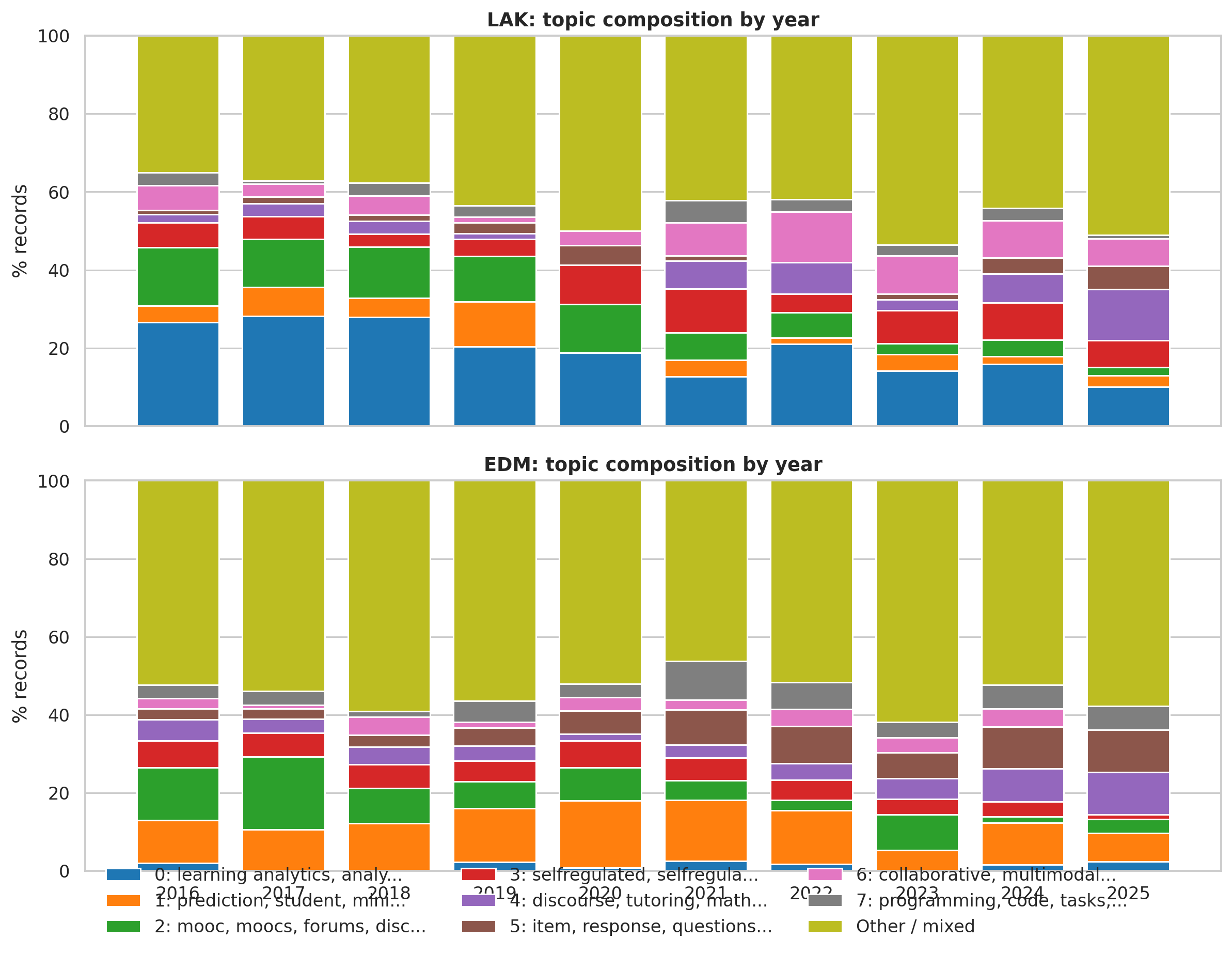
Ten-year movement is best read topic by topic10년의 흐름은 토픽별로 읽는 편이 가장 좋다
The topic model is title-only, so trend claims should be phrased as signals, not final field history. Still, selected topics show useful onboarding patterns.토픽 모델은 제목 전용이므로, 추세 주장은 최종 분야사가 아니라 신호로 표현되어야 한다. 그래도 선택된 토픽들은 유용한 안내 패턴을 보여 준다.
Use the trend explorer to avoid one-shot stereotypes. "Learning analytics / dashboards" is consistently LAK-centered, but not absent from EDM. "Prediction / performance" is consistently EDM-centered. "Collaboration / multimodal" becomes more visible in LAK after 2021. "Language models / reading" rises in both venues around 2024-2025, with stronger EDM counts in this title-only model. "Knowledge tracing" remains a clear EDM anchor, while LAK has occasional but smaller entries.추세 탐색기를 활용해 단편적 고정관념을 피하세요. "학습분석 / 대시보드"는 일관되게 LAK 중심이지만, EDM에 부재하지는 않다. "예측 / 성과"는 일관되게 EDM 중심이다. "협력 / 멀티모달"은 2021년 이후 LAK에서 더 가시화된다. "언어 모델 / 읽기"는 두 학회 모두에서 2024–2025년경에 상승하며, 이 제목 전용 모델에서는 EDM 카운트가 더 강하다. "지식 추적"은 명확한 EDM 앵커로 남고, LAK는 가끔 등장하지만 더 작다.
The right takeaway is field movement, not a fixed taxonomy. LA and EDM borrow methods from each other; what persists is the difference in rhetorical center: pedagogical action versus computational evidence.제대로 된 시사점은 분야의 흐름이지 고정된 분류 체계(taxonomy)가 아니다. LA와 EDM은 서로의 방법을 빌린다. 지속되는 것은 수사적 중심(rhetorical center)의 차이다: 교육 실천 대 계산적 증거(computational evidence).
Use this as a framing decision tool프레이밍 의사결정 도구로 사용하라
For a new paper, proposal, or teaching module, choose the field framing by what the contribution must persuade readers to believe.새 논문·제안서(proposal)·강의 모듈을 만들 때는 기여(contribution)가 독자를 무엇으로 설득해야 하는지에 따라 프레이밍(framing)을 잡아라.

Framing map. If the contribution is a better decision, feedback loop, stakeholder representation, or learning design, foreground LA. If it is a better model, prediction, validation, or benchmark, foreground EDM.프레이밍 지도. 기여가 더 나은 의사결정·피드백 루프·이해관계자 표상·학습 설계라면 LA를 전면에 둔다. 더 나은 모델·예측·검증·벤치마크라면 EDM을 전면에 둔다.
LAK framing is stronger when...LAK 프레이밍이 적합한 경우
EDM framing is stronger when...EDM 프레이밍이 적합한 경우

Paper anatomy. LA papers tend to make the educational interpretation and action chain visible; EDM papers tend to make the modeling, validation, and benchmark chain visible.논문 해부. LA 논문은 교육적 해석과 행동의 사슬을 가시화하는 경향이 있고, EDM 논문은 모델링·검증·벤치마크의 사슬을 가시화하는 경향이 있다.
What the current evidence can and cannot support현재 증거가 지원할 수 있는 것과 없는 것
The guide is suitable for onboarding, blog writing, and scoping a deeper review. It is not yet a publication-grade systematic review.이 가이드는 입문자 안내, 블로그 작성, 더 깊은 검토의 범위 잡기에 적합하다. 아직 출판 등급의 체계적 문헌 고찰은 아니다.
Extraction method추출 방법
Each venue-year query used DBLP's table-of-contents facet: toc:db/conf/<venue>/<venue><year>.bht:. The analytic filter removed title-marked workshops, tutorials, doctoral consortium items, front matter, prefaces, panels, keynotes, and symposium records.각 학회-연도 질의는 DBLP의 목차 패싯을 사용했다: toc:db/conf/<venue>/<venue><year>.bht:. 분석 필터는 제목에 표시된 워크숍·튜토리얼·박사 컨소시엄 항목·전면 자료·서문·패널·기조강연·심포지엄 레코드를 제거했다.
Current limitations현재 한계
BERTopic used titles only. Method and data-context tags are keyword heuristics. DOI coverage is partial: 823 records have DOI strings in the current DBLP extraction. Claims about "what the field believes" should be enriched with abstracts, author networks, venue tracks, and human-coded samples.BERTopic은 제목만 사용했다. 방법·데이터 맥락 태그는 키워드 휴리스틱이다. DOI 적용 범위는 부분적이다: 현재 DBLP 추출에서 823건이 DOI 문자열을 가진다. "분야가 무엇을 믿는가"에 대한 주장은 초록·저자 네트워크·학회 트랙·인간 코딩된 표본으로 보강되어야 한다.
Static figure archive정적 그림 보관소
The original PNG figures remain available for export or slides, but this page now treats the interactive charts as the primary reading surface.원본 PNG 그림은 내보내기나 슬라이드용으로 여전히 이용 가능하지만, 이 페이지는 이제 인터랙티브 차트를 주된 읽기 표면으로 다룬다.